رگرسیون لجستیک (Logistic Regression)
خلاصه مقاله
یک روش آماری است که برای مدل سازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده می شود. در درجه اول برای حل مسائل طبقه بندی باینری استفاده می شود
رگرسیون لجستیک(Logistic Regression):
رگرسیون لجستیک یک روش آماری است که برای مدل سازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده می شود. در درجه اول برای حل مسائل طبقه بندی باینری استفاده می شود که در آن متغیر وابسته دارای دو سطح است. از رگرسیون لجستیک به طور گسترده ای در زمینه های مختلف از جمله یادگیری ماشینی، تحقیقات پزشکی و علوم اجتماعی استفاده می شود.
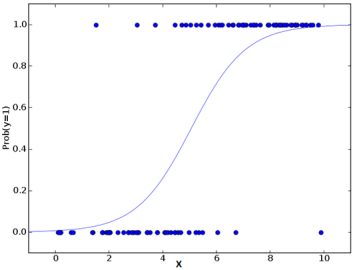
در رگرسیون لجستیک، متغیر وابسته به عنوان تابعی از متغیرهای مستقل با استفاده از تابع لجستیک (همچنین به عنوان تابع سیگموئید شناخته می شود) مدل می شود. تابع لجستیک هر عدد با ارزش واقعی را به مقداری بین 0 و 1 نگاشت می کند، که نشان دهنده احتمال تعلق متغیر وابسته به یک کلاس خاص است.
فرمول رگرسیون لجستیک به شرح زیر است:
P(Y=1|X) = 1 / (1 + e^(-Z))
که در آن:
P(Y=1|X) احتمال 1 بودن متغیر وابسته Y با توجه به متغیر پیش بینی X است. e پایه لگاریتم طبیعی است (تقریباً 2.71828). z ترکیب خطی متغیرهای پیش بینی است که با ضرایب مربوطه آنها وزن می شود.
فرمول را می توان به صورت زیر گسترش داد:
Z = β0 + β1X1 + β2X2 + ... + βn*Xn
که در آن:
z ترکیب خطی متغیرهای پیش بینی کننده است. β0، β1، β2، ...، βn ضرایب مدل رگرسیون لجستیک هستند. X1، X2، ...، Xn متغیرهای پیش بینی هستند.
برای تخمین ضرایب (β0، β1، β2، ...، βn) از الگوریتمهای بهینهسازی مختلف مانند برآورد حداکثر درستنمایی استفاده میشود.
در اینجا چند نکته کلیدی در مورد رگرسیون لجستیک را بیان خواهیم کرد:
· این یک نوع تحلیل رگرسیونی است که در آن متغیر وابسته باینری است (به عنوان مثال بله/خیر، درست/نادرست، 0/1).
· رگرسیون لجستیک از تابع لجستیک (همچنین به عنوان تابع سیگموئید شناخته می شود) برای مدل سازی رابطه بین پیش بینی کننده ها و احتمال نتیجه استفاده می کند.
· تابع لجستیک هر عدد با ارزش واقعی را به مقداری بین 0 و 1 ترسیم می کند، که نشان دهنده احتمال نتیجه باینری است.
· مدل ضرایب متغیرهای پیش بینی کننده را برای تعیین تأثیر آنها بر نتیجه تخمین می زند.
· رگرسیون لجستیک می تواند متغیرهای پیش بینی کننده طبقه بندی و پیوسته را مدیریت کند.
برای ایجاد مدل رگرسیون لجستیک به یکسری شرایط و پیش فرض ها نیاز خواهیم داشت:
· نتیجه باینری: رگرسیون لجستیک زمانی مناسب است که متغیر وابسته دودویی یا دوگانه باشد، به این معنی که تنها دو نتیجه ممکن دارد.
· خطی بودن: رگرسیون لجستیک یک رابطه خطی بین متغیرهای مستقل و شانس نتایج را فرض می کند. این را می توان از طریق تکنیک هایی مانند ترسیم منطق نتیجه در برابر متغیرهای مستقل ارزیابی کرد.
· استقلال مشاهدات: رگرسیون لجستیک فرض می کند که مشاهدات مستقل از یکدیگر هستند. این بدان معنی است که مشاهدات نباید تحت تأثیر یکدیگر قرار گیرند یا هیچ شکلی از خوشه بندی را نشان دهند.
· عدم وجود چند خطی: متغیرهای مستقل نباید همبستگی بالایی با یکدیگر داشته باشند. چند خطی می تواند منجر به تخمین های ناپایدار و مشکلات در تفسیر شود.
· حجم نمونه کافی: رگرسیون لجستیک به تعداد کافی مشاهدات برای به دست آوردن تخمین های قابل اعتماد نیاز دارد. به عنوان یک قاعده کلی، توصیه می شود حداقل 10-20 مورد با کمترین فراوانی پیامد در هر متغیر مستقل داشته باشید.
منبع:
https://onlinelibrary.wiley.com/doi/10.1111/j.1553-2712.2011.01185.x
مقالات مرتبط
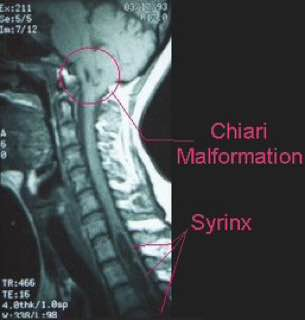
ناهنجاری کیاری
کیاری مالفورماسیون مجموعه ای از اختلالات مغز خلفی ( hidbrain) است که از هرنی تونسیل مخچه از سوراخ فورامن مگنوم تا آپلازی و آژنزی مخچه متغیر میباشد.در این مجموعه از اختلالات، علایم بالینی، یافته های تصویر برداری و جنبه های تکنیکال برای فشاربرداری (decompression) مختلفی در هر نوع از کیاری وجود دارد. چندین نوع دارد. تیپ یک : پایین آمدن تونسیل مخچه از فورامن مگنوم 5 میلیمتر یا بیشتر که سیرنگومیلیا است . علایم بصورت سردردی در پشت سر و گردن که با سرفه یا عطسه یا زورزدن ایجاد میشود و بلافاصله بعد از پایان آن ها، پایان میابد. در نوزادان و کودکانی که نمیتوانند درد خود را بیان کنند علایم آن شامل بیقراری و گریه است.نشانه های این بیماران شامل: آتاکسی، هایپررفلکسی، آتروفی، ضعف عضلانی، و اختلال عملکردی اعصاب مغزی تحتانی و از دست رفتن حس شال, اختلال حس دمایی و لمس فقط در سطحی مشاهده میشود که مسیر اسپاینوتالامیک تحت فشار قرار گرفته است.تصویر برداری انتخابی در این بیماران MRI است. در افراد نرمال و بدون علامت تونسیل مخچه میتواند تا 3 میلیمتر به پایین تر از فورامن مگنوم آمده باشد. زمانی میگوییم فتق تونسیلار رخ داده است که این پایین آمدگی 5 میلیمتر یا بیشتر باشد و در پایین آمدگی در حد فاصل 3 تا 5 میلیمتر را Borderline میگوییم.علاوه بر محل قرار گیری نوک تونسیل، شکل آن نیز مهم است. تیپ 2 : در همراهی با میلیودیسپلازی و هیدروسفالی دیده و ساختارهایی که هرنی میابند شامل:الف) ورمیس مخچه ب)ساقه ی مغزی ج) بطن چهارم هستند. علاوه بر ساختمان های عصبی مذکور ساختار های همراه آن ها نیز مانند شبکه ی کورویید، شریان بازیلار و PICA میتوانند به پایین جابجا شوند. بیماران در 5 سالگی دچار علایم ناشی از ساقه ی مغزی و یک سوم از آن ها ثانویه به نارسایی تنفسی میمیرند.از اختلال عملکرد زوج 9 و 10 مغزی دارند که میتواند تنفس، بلع و عملکرد طناب های صوتی است که میتواند در همراهی با استریدور، اپیستوتونس ونیستاگموس باشد. با طویل شدن و جابجایی به پایین ورمیس مخچه و ساقه ی مغزی، همراه با میلیومننگوسل در تمام بیماران و هیدروسفالی در اغلب بیماران و نیز وجود سیرنگومیلیا بویژه در بخش پایین نخاع گردنی بطور شایع مطرح میشود. تیپ 3 :مخچه و ساقه ی مغزی به داخل انسفالوسل قرار گرفته داخل حفره ی خلفی فتق پیدا میکند. تشخیص افتراقی این نوع از کیاری، میلومننگوسل بخش فوقانی نخاع گردنی است . تیپ 4 : آپلازی یا هایپوپلازی مخچه میباشد واندازه ی حفره ی خلفی نرمال است و هیچگونه هرنی مخچه ای وجود ندارد. تیپ 0:سیرنگومیلیا بدون وجود هرنی تونسیلار میباشد که به فشاربرداری حفره ی خلفی به خوبی پاسخ میدهد. تیپ 1.5: تونسیل مخچه با همراه با ساقه ی مغزی از فورامن مگنوم هرنی میکند
